Field Log · Entry
하네스 엔지니어링이란? AI 에이전트 환경 설계 7축 로드맵 (1/8)

ChatGPT가 나온 지 3년이 지났는데도 “AI 코딩 도구 도입했더니 오히려 디버깅에 시간 더 쓴다”는 말을 자주 듣습니다. 프롬프트는 잘 썼는데 결과가 안정적이지 않은 이유는 거의 같습니다. 모델 바깥의 환경이 설계되지 않았기 때문입니다. 이 글은 그 환경을 체계적으로 설계하는 하네스 엔지니어링을 한 편에 정리합니다.
한 줄로 말하면 “AI 모델 바깥의 규칙·도구·기억·권한·역할·검증을 체계적으로 설계하는 방법론”이고, Claude Code·OpenCode·OpenClaw를 공통 예시로 씁니다.
이 글이 답하는 질문
- 하네스 엔지니어링이란 무엇이고, 프롬프트 엔지니어링과 뭐가 다른가?
- 에이전트 루프(agent loop)는 어떻게 동작하는가?
- 하네스의 7가지 설계 축은 무엇이고, 어디서부터 시작해야 하는가?
이 시리즈가 처음이라면 — 추천 진입 순서
8편 전부를 순서대로 읽는 것보다, 다음 4편을 먼저 보고 흐름이 잡힌 다음 나머지를 펼치는 쪽이 효율적입니다.
1편 → 2편 → 5편 → 8편
- 1편 (현재) — 7축 개념과 에이전트 루프
- 2편 — 과업 분해 — 가장 자주 부딪히는 “작업을 너무 크게 던졌다” 문제
- 5편 — 권한 설정 — 안전한 자동화의 핵심
- 8편 — 검증 루프 — 같은 실수를 반복하지 않는 환경
나머지 3·4·6·7편은 위 4편을 읽다가 막히는 곳이 생기면 그때 펼치는 게 효율적입니다.
프롬프트 잘 쓰면 되는 거 아닌가?
“프롬프트를 잘 쓰면 AI가 잘 일한다”는 말은 반만 맞습니다.
AI에게 “이 앱을 리팩토링해줘”라고 잘 쓴 프롬프트를 주면, 처음에는 그럴듯하게 동작합니다. 그런데 작업이 커지고, 세션이 끊기고, 여러 파일을 건드려야 하면 문제가 생깁니다. 엉뚱한 파일을 수정하고, 어제 한 결정을 잊어버리고, 위험한 명령을 확인 없이 실행하기도 합니다.
이건 AI가 멍청해서가 아닙니다. 환경이 충분히 설계되지 않아서입니다.
OpenAI도 에이전트 시대의 엔지니어링이 코드 작성보다 “환경 설계, 의도 명세, 피드백 루프 설계”로 옮겨간다고 설명합니다(OpenAI — Practices for Governing Agentic AI Systems). Anthropic도 긴 작업에서는 프롬프트만이 아니라 세션 사이를 잇는 메모리와 구조가 중요하다고 말합니다(Claude Code Best Practices).
이 “환경 설계”를 체계적으로 하는 것이 하네스 엔지니어링입니다.
하네스 엔지니어링 = AI의 작업 환경 전체를 설계하는 것
한 줄로 정의하면:
AI 모델 바깥의 규칙, 도구, 기억, 권한, 역할, 검증 구조를 설계해서, AI가 안전하고 안정적으로 일할 수 있게 만드는 방법론
비유하면 이렇습니다. AI 모델은 뇌이고, 하네스는 그 뇌가 일할 수 있게 해주는 몸통 전체입니다.
- 프롬프트 엔지니어링 → 뇌에 말을 거는 기술
- 하네스 엔지니어링 → 뇌를 둘러싼 환경을 설계하는 기술
프롬프트는 하네스의 일부일 뿐이고, 하네스는 훨씬 넓은 개념입니다.
프롬프트 엔지니어링 vs 하네스 엔지니어링 - 6가지 차이
| 관점 | 프롬프트 엔지니어링 | 하네스 엔지니어링 |
|---|---|---|
| 대상 | 모델 입력 문자열 | 모델 바깥 환경 전체 |
| 단위 | 세션 내 (휘발) | 프로젝트·조직 (영속) |
| 산출물 | 잘 쓴 prompt 텍스트 | CLAUDE.md, settings.json, subagent 정의, hooks |
| 실패 모드 | 같은 프롬프트를 반복 작성 | 같은 실수를 반복 기록·보강 |
| 초기 투자 | 낮음 | 중간 (3~5시간) |
| 장기 수익 | 세션당 | 누적 |
프롬프트 엔지니어링은 하네스 엔지니어링의 **한 축(입력 설계)**일 뿐입니다. 같은 프롬프트를 매번 새로 짜기보다, 환경을 문서로 고정해 두면 “한 번 만든 규칙을 수백 세션이 공유”하는 복리 효과가 생깁니다.
에이전트 루프 — 하네스의 심장
하네스가 실제로 돌아가는 핵심 메커니즘은 **에이전트 루프(Agent Loop)**입니다.
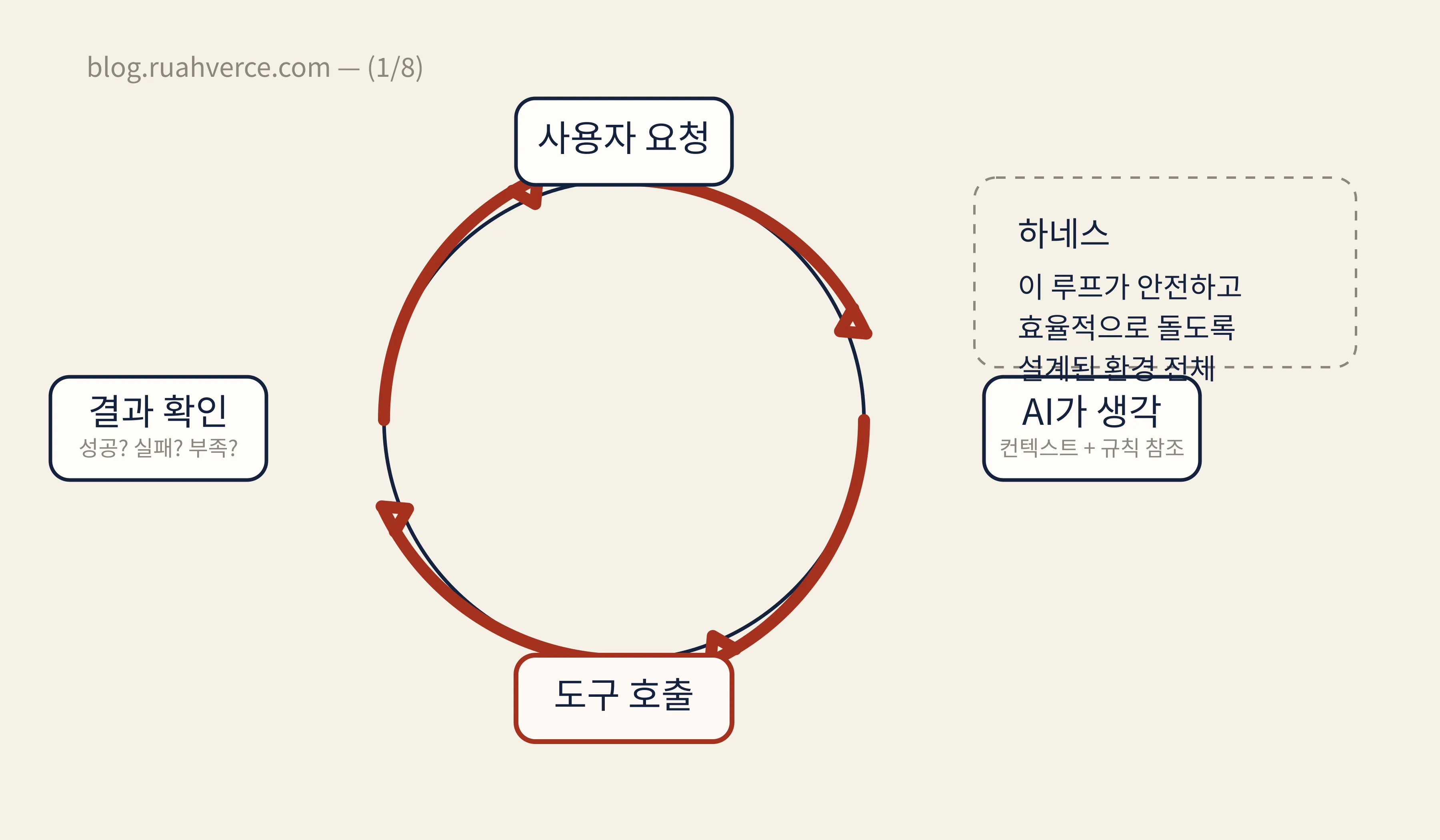
AI가 한 번 답하고 끝나는 게 아니라, 생각 → 도구 호출 → 결과 확인 → 다시 생각을 반복하는 구조입니다. 하네스는 이 루프가 안전하고 효율적으로 돌도록 주변을 설계하는 것입니다.
하네스의 7가지 축 — 시리즈 전체 로드맵

하네스 엔지니어링을 공부할 때 반복적으로 나타나는 설계 축이 7개 있습니다. 이 시리즈는 이 7축을 하나씩 다룹니다.
| # | 축 | 한 줄 설명 | 핵심 키워드 | 이 시리즈에서 |
|---|---|---|---|---|
| 1 | 과업 분해 | 큰 일을 작은 단위로 나누기 | task decomposition | (2/8) 읽기 |
| 2 | 지식 구조화 | CLAUDE.md로 프로젝트 맵 만들기 | CLAUDE.md, AGENTS.md | (3/8) 읽기 |
| 3 | 도구 설계 | Tool, Skill, Plugin, MCP 구성 | MCP, Tool Use | (4/8) 읽기 |
| 4 | 권한 설정 | allow/ask/deny로 안전하게 자동화 | permissions, hooks | (5/8) 읽기 |
| 5 | 메모리 패턴 | 세션 끊겨도 기억 유지 | PROGRESS.md, —continue | (6/8) 읽기 |
| 6 | 역할 분리 | subagent로 전문 역할 위임 | subagent, orchestrator | (7/8) 읽기 |
| 7 | 검증 루프 | hooks와 실패 로그로 자동 점검 | PostToolUse, feedback loop | (8/8) 읽기 |
이 7개를 한 번에 완벽하게 만들 필요는 없습니다. CLAUDE.md부터 시작해서(2편 “지식 구조화”), 에이전트가 막히는 곳이 보일 때마다 검증 루프(8편 “검증과 반복”)로 되먹이는 방식이 가장 실용적입니다.
이 시리즈에서 다루는 도구들
이 시리즈는 세 가지 도구를 기준으로 설명합니다.
- Claude Code — Anthropic의 코딩 에이전트. CLAUDE.md, 권한(allow/ask/deny), 훅(hooks), subagent를 제공
- OpenCode — 오픈소스 코딩 에이전트. AGENTS.md, 모드, 플러그인을 제공
- OpenClaw — 멀티에이전트 게이트웨이. SOUL.md, USER.md, workspace 격리를 제공
세 도구가 같은 원리를 다른 형태로 구현하고 있어서, 비교하면서 보면 하네스 엔지니어링의 핵심이 더 선명해집니다.
하네스 엔지니어링은 누가 해야 하나?
AI 에이전트를 사용하는 모든 개발자에게 해당합니다. 특히:
- Claude Code, Cursor, Copilot 같은 AI 코딩 도구를 쓰고 있다면 → 이미 하네스의 일부를 쓰고 있는 것. 이걸 의식적으로 설계하면 효과가 극적으로 달라집니다.
- AI 에이전트를 만들고 있다면 → 에이전트가 안정적으로 동작하려면 하네스 설계가 필수입니다.
- AI 도구의 효율을 높이고 싶다면 → 프롬프트 개선만으로는 한계가 있고, 환경 설계가 답입니다.
내가 실제로 부딪힌 문제와 해결 (1인칭 경험)
이 시리즈와 블로그 레포를 정리하면서 가장 먼저 체감한 건, 프롬프트 문장만 다듬어서는 결과 편차가 잘 줄지 않는다는 점이었습니다. 글 초안 생성, 이미지 렌더링, frontmatter 검증, 배포 확인처럼 모델 바깥 절차가 조금만 흔들려도 같은 요청이 다른 품질로 돌아왔습니다. 문제는 답변 문장보다 어디를 읽고, 어디를 수정하고, 무엇으로 검증할지가 고정되지 않았다는 데 있었습니다.
그래서 이 레포에서는 CLAUDE.md, 시리즈 구조, 이미지 자산 규칙, 빌드 검증 순서를 먼저 고정했습니다. 그 뒤부터는 “좋은 답을 한 번 받는 것”보다 “비슷한 품질을 반복해서 얻는 것”이 훨씬 쉬워졌습니다. 제 기준에서 하네스 엔지니어링은 프롬프트를 더 잘 쓰는 기술이라기보다, 같은 요청이 들어와도 흔들리지 않게 만드는 작업 환경 설계에 더 가깝습니다.
자주 묻는 질문 (FAQ)
Q1. 하네스 엔지니어링은 프롬프트 엔지니어링과 뭐가 다른가요? 프롬프트 엔지니어링은 “AI에게 뭐라고 말할까”에 집중합니다. 하네스 엔지니어링은 그보다 넓게, AI가 일하는 환경 전체 — 어떤 파일을 읽을 수 있고, 어떤 도구를 쓸 수 있고, 뭘 기억하고, 뭘 자동 실행할 수 있는지 — 를 설계합니다. 프롬프트는 하네스의 일부입니다.
Q2. 하네스 엔지니어링은 꼭 코딩 에이전트에만 해당하나요? 아닙니다. 코딩 에이전트(Claude Code, Cursor)에서 가장 체계화되어 있지만, 원리는 모든 AI 에이전트에 적용됩니다. 데이터 분석 에이전트, 고객 지원 에이전트, 리서치 에이전트 모두 “환경 설계”가 필요합니다.
Q3. 7축을 전부 설정해야 시작할 수 있나요? 아닙니다. CLAUDE.md 3줄 + 기본 권한 설정이면 충분합니다. 에이전트가 막히는 곳이 보일 때마다 해당 축을 한 층씩 보강하는 것이 가장 빠른 방법입니다. 마지막 편 검증과 반복에서 이 과정을 자세히 다룹니다.
Q4. Claude Code 외에 다른 도구에도 적용할 수 있나요? 네. 이 시리즈는 Claude Code, OpenCode, OpenClaw 세 도구를 비교하면서 설명합니다. 도구마다 파일 이름이나 설정 형식은 다르지만, 7축의 원리는 동일합니다.
Q5. 하네스 엔지니어링은 얼마나 투자해야 ROI가 나오나요?
경험상 CLAUDE.md 50줄 + 기본 권한(allow/ask/deny) 설정까지는 초기 35시간이면 충분합니다. 이 기본만으로도 “같은 실수를 반복하지 않는” 효과가 보입니다. 7축 전체를 갖추는 건 24주 점진적으로 진행합니다.
Q6. 팀에서 도입할 때 어디서부터 시작하나요? 개인 실험 → CLAUDE.md 공유 → 권한 규칙 팀 템플릿화 → subagent 도입 순으로 권장합니다. 팀 전체가 한 번에 도입하면 “규칙만 만드는 오버헤드”가 생기므로, 한 명이 먼저 패턴을 확립한 뒤 확산시키는 편이 정착률이 높습니다.
마무리
- 하네스 엔지니어링은 프롬프트가 아니라 AI 모델 바깥의 환경 전체를 설계하는 방법론입니다.
- 에이전트 루프(생각 → 도구 호출 → 결과 확인 → 다시 생각)를 안전하게 굴리는 것이 핵심입니다.
- 7축(분해·지식·도구·권한·메모리·역할·검증)을 한 번에 다 할 필요 없이, CLAUDE.md부터 시작해 막히는 곳을 보강해 나가면 됩니다.
다음에 읽으면 좋은 글
- (2/8) AI 에이전트 과업 분해 — 큰 작업을 안전하게 쪼개는 4가지 기준
- (3/8) CLAUDE.md 작성 가이드 — 지식 구조화의 3계층 원칙
- (8/8) 검증 루프 설계 — 실패 로그와 Hooks로 하네스를 강화하는 법