Field Log · Entry
AI 에이전트 검증 루프 설계 — 실패 로그 패턴과 Hooks 자동화 (8/8)
지난 7편을 통해 7축을 다 만들었다고 해도 에이전트는 여전히 막힙니다. 새로운 작업, 새로운 코드베이스, 새로운 실수가 계속 생기기 때문입니다. 좋은 하네스의 마지막 조각은 막힐 때마다 자기 자신을 보강하는 루프입니다.
결론부터 말하면, 에이전트가 막히는 지점을 실패 로그로 남기고, 해당 축만 Hooks로 보강하는 4단 루프(관찰 → 진단 → 보강 → 검증)가 가장 효과적이었습니다. 앞 편을 읽지 않아도 이 글 하나로 핵심을 이해할 수 있도록 필요한 개념은 본문에서 짧게 요약합니다.
이 글이 답하는 질문
- 에이전트가 같은 실수를 반복하는 걸 어떻게 막나?
- Hooks(PreToolUse/PostToolUse)로 어떤 자동 검증이 가능한가?
- 실패 로그는 어떻게 남기고 어떻게 다음 개선으로 연결하나?
시리즈 안내 — 이 글은 하네스 엔지니어링 시리즈의 8/8 마지막 편입니다. 시리즈를 처음 본다면 1편 — 7축 로드맵 부터 읽으면 전체 흐름이 깔끔하게 잡힙니다.
왜 검증 루프가 먼저 필요한가
하네스는 한 번 만들고 끝나는 게 아니라, 에이전트가 막히는 지점을 관찰하고, 해당 축을 보강하는 반복이 핵심입니다.
OpenAI도 엔지니어의 핵심 일이 결국 “에이전트가 안정적으로 일하게 하는 feedback loop 설계”라고 설명합니다(OpenAI — Practices for Governing Agentic AI Systems).
개선 루프 4단계
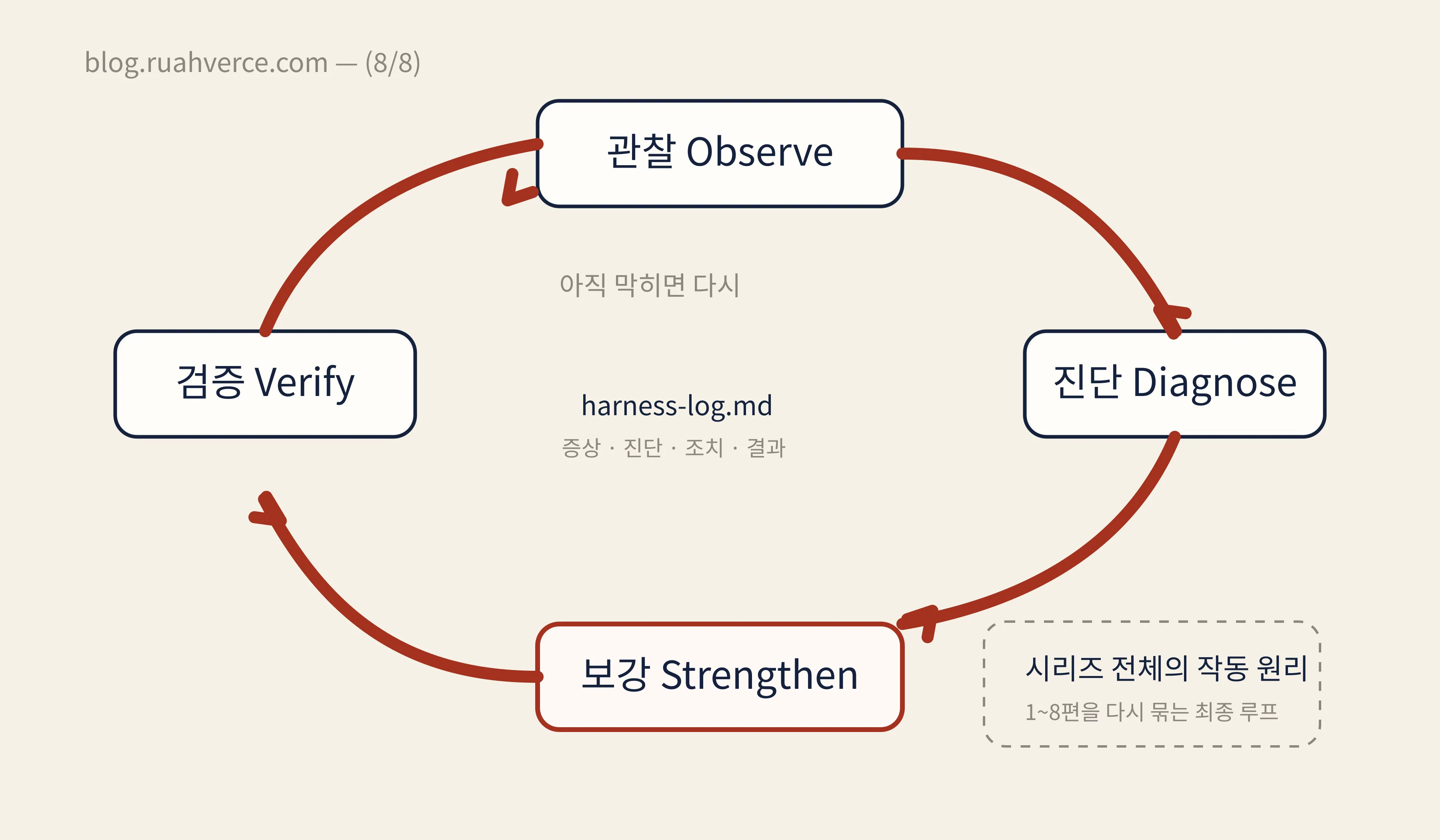
- 관찰: 에이전트가 어디서 막히는가?
- 진단: 7축 중 어디가 약한가?
- 보강: 해당 축을 고친다
- 검증: 같은 상황에서 재시도한다
증상 → 진단 → 처방 매핑

아래 표는 에이전트의 증상을 7축으로 역추적하는 진단 키트입니다. 즐겨찾기해 두고 막힐 때마다 펼치면 됩니다.
| 증상 | 원인 (축) | 처방 |
|---|---|---|
| 엉뚱한 파일을 수정 | 축2 지식 | CLAUDE.md에 디렉터리 역할 추가 ((3/8) 지식 구조화) |
| 같은 실수를 반복 | 축5 메모리 | PROGRESS.md 도입, —continue 활용 ((6/8) 메모리 패턴) |
| 한 번에 너무 많이 변경 | 축1 분해 | ”파일 3개 이상 동시 수정 금지” 규칙 ((2/8) 과업 분해) |
| “할 수 없다”며 멈춤 | 축3 도구 | MCP 서버 추가, SKILL.md 작성 ((4/8) 도구 설계) |
| 위험한 명령을 확인 없이 실행 | 축4 권한 | allow/ask/deny 조정 ((5/8) 권한 설정) |
| 품질이 들쭉날쭉 | 축6 역할 | 리뷰어 subagent 분리 ((7/8) 역할 분리) |
| “완료”인데 버그가 있음 | 축7 검증 | PostToolUse 훅으로 자동 테스트 |
에이전트가 막히는 곳 = 하네스가 약한 곳입니다. 문제는 “에이전트가 멍청해서”가 아니라 “환경이 설계되지 않아서”인 경우가 대부분입니다.
훅으로 자동 검증 만들기
검증 루프의 핵심 도구는 **훅(hook)**입니다 (Anthropic — Claude Code Hooks 공식 문서).
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write",
"command": "npx eslint --fix $CLAUDE_FILE_PATH 2>&1 | tail -5"
}
],
"PreToolUse": [
{
"matcher": "Bash",
"command": "echo \"$(date): $CLAUDE_TOOL_INPUT\" >> .claude/audit.log"
}
]
}
}훅의 타이밍:
SessionStart → UserInput → PreToolUse → 도구 실행 → PostToolUse → ...반복... → SessionEnd- PreToolUse: 도구 실행 전. 차단, 로깅, 입력 수정 가능.
- PostToolUse: 도구 실행 후. 자동 린트, 테스트, 검증 가능.
- SubagentStart/Stop: subagent 시작/종료 시. 컨텍스트 주입, 결과 로깅.
실전 시나리오: 3번의 개선 사이클
사이클 1 — 에이전트가 엉뚱한 파일 수정
- 관찰: “로그인 버그 고쳐줘”에 auth/ 대신 components/를 수정
- 진단: 축2 (지식) — 디렉터리 역할 미명시
- 보강: CLAUDE.md에 디렉터리 맵 추가
- 결과: 이후 같은 문제 재발 안 함
사이클 2 — 고쳤는데 테스트 실패
- 관찰: 맞는 파일을 수정했지만 “완료” 후 테스트 3개 실패
- 진단: 축7 (검증) — 자동 테스트 없음
- 보강: PostToolUse 훅에 자동 테스트 추가
- 결과: 이후 수정마다 테스트 자동 실행
사이클 3 — 기능은 되지만 보안 취약점
- 관찰: SQL injection 방어가 빠져 있음
- 진단: 축6 (역할) — 코딩 에이전트가 보안까지 챙기기 어려움
- 보강: security-reviewer subagent 추가
- 결과: 코드 수정 후 자동으로 보안 리뷰 위임
한 사이클마다 하네스가 한 층씩 단단해집니다.
실패를 기록하라
개선의 시작은 관찰이고, 관찰의 기록이 실패 로그입니다.
# harness-log.md
## 2026-04-02
### 실패: 엉뚱한 파일 수정
- 증상: auth/ 대신 components/ 수정
- 진단: 축2 — 디렉터리 역할 미명시
- 조치: CLAUDE.md에 디렉터리 맵 추가
- 결과: 해결
### 실패: 수정 후 테스트 미실행
- 증상: "완료"인데 테스트 3개 실패
- 진단: 축7 — 자동 테스트 없음
- 조치: PostToolUse 훅 추가
- 결과: 해결매번 상세하게 쓸 필요 없습니다. 증상-진단-조치-결과 4줄이면 충분합니다.
보강 우선순위
높은 우선순위 (처음에 바로)
- CLAUDE.md 작성/보강 - 축2
- 기본 권한 설정 - 축4
- 린트/테스트 훅 추가 - 축7
중간 우선순위 (문제가 보일 때)
- PROGRESS.md 도입 - 축5
- 과업 분해 규칙 명시 - 축1
- MCP 서버/스킬 추가 - 축3
낮은 우선순위 (안정된 후)
- subagent 분리 - 축6
- PreToolUse 훅 세밀화 - 축7
- agent team 구성 - 축6
3가지 핵심 습관
첫째, 실패를 기록한다. 같은 축에서 반복 실패하면 근본 설계가 약하다는 신호입니다.
둘째, 한 번에 하나만 고친다. 여러 축을 동시에 바꾸면 뭐가 효과 있었는지 모릅니다.
셋째, 처음부터 완벽하게 만들지 않는다. CLAUDE.md 3줄 + 권한 + 훅 하나로 시작하고, 막히는 곳마다 한 층씩 쌓는 게 가장 빠릅니다.
내가 실제로 부딪힌 문제와 해결 (1인칭 경험)
검증 루프의 필요성은 “고쳤는데 다시 같은 문제가 보이는” 순간마다 더 분명해졌습니다. 예를 들어 이미지를 넣고 메타를 보강했는데도, 실제 라이브 HTML이나 사이트맵을 확인해 보면 기대한 신호가 빠져 있는 경우가 있었습니다. 코드상으로는 끝난 것처럼 보여도, 빌드 결과와 배포 결과까지 보면 놓친 축이 드러나는 식입니다.
그래서 지금은 수정 자체보다 읽기 → 수정 → 빌드 → 렌더된 HTML 확인 → 사이트맵/메타 확인 순서를 더 중요하게 봅니다. 제 기준에서 검증 루프는 실패를 줄이는 장치이기도 하지만, 그보다 무엇을 다음 규칙으로 승격할지 찾는 장치에 가깝습니다. 한 번 잡은 실패 패턴을 훅이나 체크리스트로 옮겨두면, 그다음부터는 같은 실수가 훨씬 덜 반복됐습니다.
자주 묻는 질문 (FAQ)
Q1. Hooks와 SKILL.md 중 뭐부터 써야 하나요? 초기에는 Hooks가 투자 대비 효과가 큽니다. 린트/테스트를 PostToolUse로 자동화하면 “완료했는데 테스트 실패” 유형의 사이클을 먼저 없앨 수 있습니다. SKILL은 에이전트가 반복적으로 동일 도구를 호출할 때 도입합니다. (관련: (4/8) 도구 설계)
Q2. 실패 로그는 어디에 저장하나요?
프로젝트 루트에 harness-log.md 또는 .claude/harness-log.md를 권장합니다. 민감한 내부 용어가 섞인다면 .gitignore에 넣어 로컬 전용으로 관리하세요.
Q3. 검증 루프에 LLM을 또 쓰는 게 비용 문제 아닌가요? 1차 검증은 Hooks의 정적 도구(eslint, pytest, ruff)로 처리하고, LLM 기반 리뷰는 security-reviewer 같은 subagent에만 위임하는 2단 구성이 비용 효율적입니다. (관련: (7/8) 역할 분리)
마무리: 검증 루프 한 장 요약
하네스 엔지니어링의 핵심은 결국 이것입니다:
프롬프트만 잘 쓰는 게 아니라, AI가 일하는 환경 전체를 설계하는 것.
7축은 외우는 게 아닙니다. 에이전트가 막힐 때 “어떤 축이 약한가?”를 진단하는 프레임워크입니다. CLAUDE.md 하나로 시작해서, 관찰하고, 보강하고, 다시 관찰하는 반복이 좋은 하네스를 만드는 유일한 길입니다.
다음에 읽으면 좋은 글
- (1/8) 하네스 엔지니어링이란? — 7축 프레임워크 전체 요약
- (3/8) CLAUDE.md 작성 가이드 — 축2 실전 설계
- (5/8) Claude Code 권한 설정 — 축4 실전 설계
시리즈를 다 읽으셨다면
- 본인 프로젝트의
CLAUDE.md를 50줄로 다이어트해 보세요. (3/8) 지식 구조화의 좋은 예를 그대로 따라가면 됩니다. .claude/settings.json에Bash(rm -rf:*)deny 한 줄을 추가하세요. (5/8) 권한 설정의 출발점입니다.harness-log.md를 만들고 다음 한 주의 실패를 기록해 보세요. 이 루프의 시작점입니다.